在CCKS2020(全国知识图谱与语义计算大会)举办的“基于本体的金融知识图谱自动化构建技术评测”任务中,我们的团队——北京网络技术服务团队,通过综合运用多种自然语言处理与知识图谱技术,最终取得了第五名的成绩。本文旨在对该次评测中所采用的核心技术方案与实现方法进行与分享。
一、 任务背景与挑战
该评测任务旨在推动金融领域知识图谱的自动化构建技术发展。参赛者需基于给定的金融领域本体(Ontology)和标注语料,设计并实现一个端到端的系统,能够从非结构化的金融文本中自动抽取实体、关系及属性,并形成符合本体规范的知识三元组,最终构建成结构化的知识图谱。核心挑战在于:
- 金融领域专业性:文本中包含大量金融术语、公司实体、金融指标,需要精准识别。
- 关系复杂性:金融实体间关系多样且定义严谨,如“控股”、“发行”、“属于”等,对关系分类精度要求高。
- 本体约束:抽取的知识必须严格遵循预先定义的本体模式(Schema),对实体链接和关系对齐提出了高要求。
- 自动化与效率:要求系统全流程自动化,并需在有限的评测时间内处理大规模文本。
二、 核心技术方法
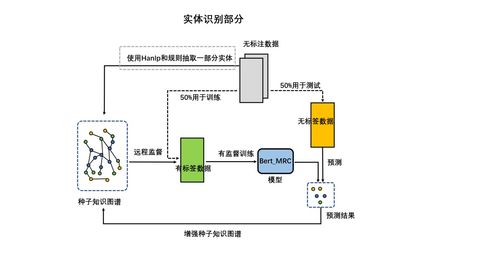
我们的解决方案采用了“管道式”(Pipeline)架构,将任务分解为命名实体识别(NER)、实体链接(Entity Linking)和关系抽取(Relation Extraction)三个核心模块,并辅以后处理与融合策略。
1. 命名实体识别(NER)模块
* 模型选择:采用预训练语言模型BERT作为基础,在其上叠加BiLSTM-CRF层,构成混合模型。BERT能够提供深层次的上下文语义表示,BiLSTM能够有效捕捉序列的长期依赖,CRF层则确保了标签预测的全局最优性。
- 领域适配:为了使模型更好地适应金融领域,我们使用了在金融新闻、财报等语料上继续预训练的BERT变体(如FinBERT或类似模型)作为初始化,显著提升了金融实体(如“市盈率”、“应收账款”)的识别准确率。
- 数据增强:针对金融标注数据有限的问题,采用了基于本体的回译和实体替换等数据增强技术,扩充了训练样本。
2. 实体链接(EL)模块
* 候选实体生成:将NER识别出的实体提及(Mention),通过字符串模糊匹配与编辑距离,在本体概念库中进行初步检索,生成候选实体列表。
- 实体消歧:构建一个基于BERT的双塔编码模型。一个塔编码文本中提及的上下文,另一个塔编码候选实体的描述文本(来自本体定义)。通过计算两者的语义相似度,选择相似度最高的候选实体作为链接目标。此方法有效解决了金融实体名称歧义(如“苹果”可能指公司或水果)和简称问题。
3. 关系抽取(RE)模块
* 联合抽取思路:为了克服传统管道方法中错误传播的问题,我们探索了基于序列标注的联合抽取模型。将关系抽取任务转化为对句子中每个token进行“实体-关系”联合标签的序列标注问题。这种方法能够同时捕捉同一句子内多个实体对的关系,提升了效率。
- 远程监督与强化学习:利用知识库(本体)中已有的三元组,对海量无标签金融文本进行远程监督标注,生成噪声数据用于模型预训练。随后在精标注数据上,采用强化学习策略对模型进行微调,以减轻噪声标签带来的负面影响,稳定提升了关系分类的F1值。
4. 后处理与知识融合
* 规则修正:根据金融领域规则和本体约束,设计了一系列后处理规则。例如,对于“公司A控股公司B”这类句子,确保抽取的“控股”关系方向正确;对数值、日期等属性进行格式化标准化。
- 冲突消解:对同一来源文本中可能产生的冗余或矛盾三元组,基于置信度(模型预测概率)和证据频次进行融合与去重,输出最可靠的知识集合。
三、 与展望
本次评测中,我们的方案通过结合预训练语言模型的强大语义理解能力、领域适配策略以及针对性的模块设计,实现了金融知识抽取的较高自动化水平。最终获得第五名,验证了方案的有效性。
主要经验:1)领域特定的预训练至关重要;2)针对金融文本特点(如长句、多实体)设计模型结构能带来增益;3)后处理规则是提升结果合规性的有效补充。
未来改进方向:1)尝试更先进的端到端联合学习模型,以进一步减少模块间的误差累积;2)引入图神经网络(GNN)对已抽取的知识进行全局推理和纠错;3)探索小样本和零样本学习技术,以应对金融本体不断演化和新增关系类型的挑战。
通过此次评测,我们深化了对金融知识图谱构建技术难点的理解,也为后续研发更智能、更鲁棒的金融信息自动化处理系统积累了宝贵经验。